OS를 다 까먹어서 복습해보기로.
1, 2챕터는 인트로여서 정리하지는 않겠다
프로세스
너무 많이 했다.
프로세스 : 실행중인 프로그램
이제 OS가 프로세스를 관리해주야 하는데 어떻게 관리할것인가? 가 관건이다
이를 이해하기 위해 프로세스의 생명주기를 이해해야 한다
프로세스 생명주기
- NEW
프로세스가 생성된 상태
- RUNNING
프로세스가 CPU를 점유해서 해당 명령어를 CPU가 처리하고 있는 상태
- WAITING
CPU가 다른 처리를 하고 있어서 기다리고 있는 상태
EX) 프로세스1이 running 상태일때 프로세스2가 기다리고 있는 상황
EX2) IO를 일으켜서 점유를 반납하는 상황
- READY
레디큐에서 CPU 점유를 대기하고 있는 상황
EX) IO를 일으키고 waiting도 끝난 다음 대기
- TERMINATED
모두 처리된 상태

PCB (process control block)
TCB라고 부르기도 한다고 한다 (task control block)
생명주기 알았고
이제 이 생명주기들을 가지는 프로세스를 정말 어떻게 관리할 것인가?가 PCB이다
-> 프로세스가 가져야할 정보를 모두 하나의 구조체에 저장하자는 아이디어가 PCB
우선 PCB는 메모리에 존재하는 자료구조이고
다음과 같은 정보들을 저장한다
- process state : 상태 (new, running 등)
- program counter : 다음으로 실행할 명령어의 메모리 주소 저장하는 레지스터 (CPU에 있겠지?)
컨텍스트 스위칭이 일어나고 다시 실행할때 다음 실행할 주소를 기억해야 하니까
- CPU 레지스터
- CPU 스케줄링 정보
- 메모리 정보
- 열린 파일 정보
등
--> 내용들을 생각해보면 PCB는 프로세스마다 하나씩 있겠구나를 생각해볼 수 있다

스레드
또 복습이긴 하다
프로세스 내부에서도 여러가지 작업을 처리학 위해 존재하는
실행하는 작업의 단위.
스레드는 나중에 다시 나온다고 한다
멀티 프로그래밍
다시 처음으로 돌아와서
멀티 프로그래밍의 목적은
동시에 여러개의 프로세스를 실행시키기 위함이다.
그래서 조합해보면 JVM 공부할때 했던 병렬 처리는 하나의 java 프로세스 안에서 스레드 여러개를 처리하는거고
지금 하고 있는 OS를 공부할때는 컴퓨터 전체 자원 관점에서 여러개의 프로세스를 동시에 실행시키는
즉 스포티파이를 키고, 브라우저를 실행하면서 워드 프로그램을 띄우는 느낌
-> 1. at the same time, simultaneously, concurrently는 동일한 의미
2. parallel (병렬적)은 약간 다른 의미
1번 concurrently는 동시성으로 정확히 번갈아가면서 실행하는거다
근데 그게 엄청 빠르니까 동시처럼 보이는 것 - time sharing과 관련된 내용
2번 parallel은 병렬성으로 진짜 물리적으로 동시에 실행하는거다
이를 달성하기 위해 사용하는 기법이 스케줄링이고 많이 나왔던게 time sharing, 그중에서도 라운드 로빈 등등..
이 스케줄링을 위해 프로세스들을 관리하는 것이 ready queue
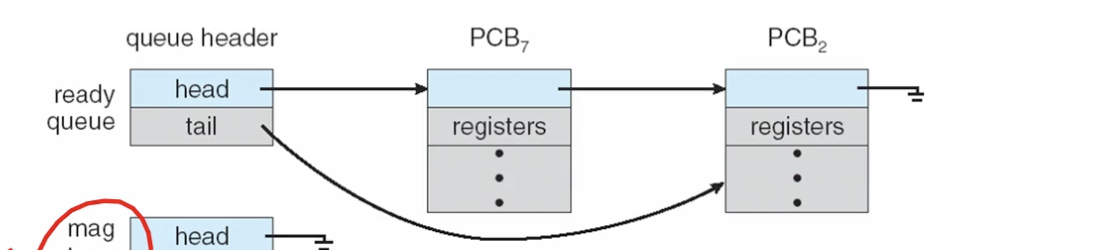
IO를 발생시키고는 waiting 상태로 들어간다고 했다
이때는 wait queue로 들어가게 될텐데
당연히 이 경우에는 큐 개수가 여러개일 것
(각 디바이스마다, 즉 인터럽트를 기다리는 대상이 다르기 때문)

다시 작성하는데, 헷갈리면 안되는게 waiting queue에서 인터럽트 받고 바로 running이 아니라 ready queue로 간다!!
context switch
context?
프로세스의 문맥
OS 입장에서는 PCB 정보가 프로세스의 context가 되겠다
interrupt 상황을 보면
현재 running중인 프로세스의 context를 저장하고 (EX) PC)
커널 모드로 들어가 다른 작업을 수행하거나 ready queue에 있는 다음 프로세스를 수행
프로세스 생성
fork()라는 system call 명령어를 사용한다면
현재 프로세스를 복제해서 자식 프로세스를 만드는 작업이다

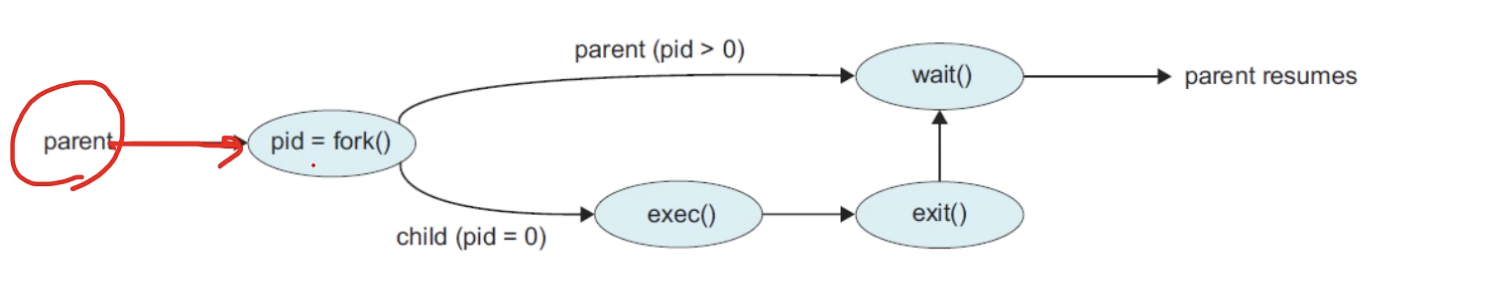
아래쪽이 자식
위쪽이 부모 프로세스
이런 과정을 거친다고 하는데 사실 잘 이해가 안간다
예시로 살펴보면
OS 입장에서는 새로운 프로그램을 위해 새로운 프로세스를 생성하는게 복잡하니까
fork()로 복제본을 생성하고, exec()로 새로운 프로그램으로 변환, 실행 후 자식 종료
그리고 그동안 부모 프로세스는 wait
이때 부모 프로세스가 wait 하지 않고 종료해버리면
자식 프로세스는 고아 프로세스가 되고, 그 상태로 계속 남아있다면 zombie process
여기서 address space도 복제한다고 하는데,
이건 아직 설명이 없다
아마 가상메모리와 관련된 내용은 뒤에서 나올 것 같다
process들은 기본적으로 독립적이다
하지만 cooperating 즉 데이터를 공유하거나 주고받을 때 문제가 생기는데
이걸 IPC라고 한다
Inter-process communication
이걸 해결하기 위해
- shared memory
- message passing
두가지 방법을 사용할 수 있다
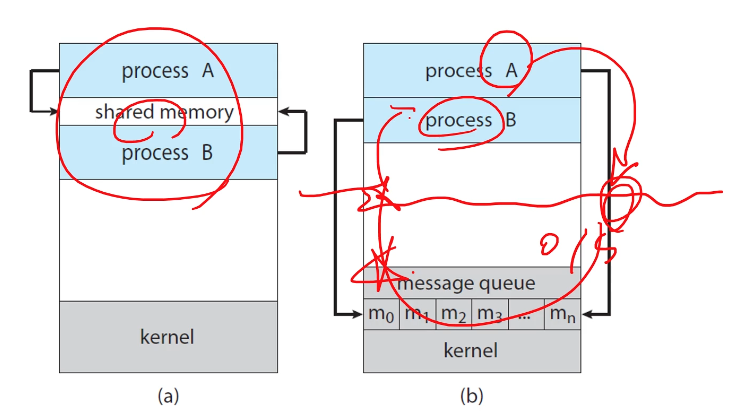
a가 shared memory
b가 message passing을 나타낸 그림이다
생산자 - 소비자 문제
항상 나오는 문제인데
문제되는 지점은
- 버퍼가 가득 찼을 때 생산자가 또 넣으려고 하면?
- 버퍼가 비었을 때 소비자가 꺼내려고 하면?
- 동시에 접근하면 데이터 꼬임
이를 해결하기 위해 a 방법이 buffer 버퍼를 shared memory로 사용하면 된다는거다
producer는 버퍼가 가득 찼을 때 버퍼에 데이터를 채우는걸 멈추고 기다리면 되고
consumer는 버퍼가 비었을 때 버퍼에서 데이터를 가져오는걸 멈추고 기다리면 된다
이 버퍼를 공유 메모리로 사용하면 될 것
(이때 동작은 time sharing 즉 concurrently 개념으로 생각하면 된다)
shared memory 방식의 문제점도 존재한다
-> 프로그램을 짜는 사람이 자체적으로 이를 해결해야한다는 문제점
이래서 나오는게 message passing 방식인데
OS 자체적으로 shared memory를 관리하고 이때 발생하는 동기화 문제를 관리하는
즉 message passing을 위한 api를 제공해 주는 개념이다
send(message)
receive(message)
이렇게 나오는 내용이 여기에 속한다
이때 message passing을 할때도
- 생산자 소비자가 직접적으로 커뮤니케이트 할것인지
- 동기적으로 / 비동기적으로 커뮤니케이트 할것인지에 대한 내용이 나온다
이걸 전문적으로 표현하면
메일박스 (port)를 사용한
- direct / indirect 방식
동기적 / 비동기적인
- blocking IO / non-blocking io
이를 표준화한 것이
Shared memory는 POSIX
Message Passing에서는 Pipes
'CS > OS' 카테고리의 다른 글
| [OS 공룡책] 6. Synchronization Tools, 7. Examples (1) | 2026.01.09 |
|---|---|
| [OS 공룡책] 5. CPU Scheduling (1) | 2026.01.09 |
| [OS 공룡책] 4. Thread & Concurrency (3) | 2026.01.08 |